
引言:我和Digital Zoo Content Team 一起重啟Digital Zoo的自家Blog寫作計劃有幾項目標,首先是作為SEO Content Hub的推手,我們當然要以身作則,建立一個我們的標準給合作夥伴及客人作榜樣。除此之外,上一篇關於Ahrefs Evolve的文章亦有提到,我希望透過公司的Blog去把國外的SEO動態帶來中文世界,尤其是香港市場。與很多業界人士交流中,言談間都了解到大家都有一種香港SEO與世界業界「脫節」的感覺,但大家忙於手頭上的工作,根本沒有多餘時間去Update香港讀者,因此我希望Digital Zoo的Blog可以在這方面略出綿力,將有價值的SEO、AIO、GEO資訊,用香港SEO從業員的角度去摘錄和翻譯。以下這篇是Ahrefs內容總監Ryan Law今年4月7日刊登於Ahrefs自家Blog的文章,此文道出了SEO與生成式引擎的關係,以及業界可以用甚麼態度去面對這個搜尋世界的變化,亦深入講述了SEO與其他LLM的性質及它們共享或排斥的可能性。
原文:https://ahrefs.com/blog/geo-is-just-seo/
作者:Ryan Law
翻譯:Andy Wong
作為一位行銷人員,我想知道是否有特定方法可以改善我們在大型語言模型(LLM)中的可見度,而這些方法並不屬於我目前例行的行銷和搜尋引擎優化(SEO)工作。到目前為止,看起來並沒有。
SEO和GEO(生成式引擎優化)之間似乎有大量重疊,以至於將它們視為不同的流程似乎沒有必要。那些有助於提高搜尋引擎可見度的因素同樣有助於提高在大型語言模型中的可見度。GEO似乎是SEO的副產品,不需要專門或額外的努力。如果你想在LLM輸出中增加曝光度,請聘請SEO專家。
附註:GEO是「生成式引擎優化」(generative engine optimization),LLMO是「大型語言模型優化」(large language model optimization),AEO是「答案引擎優化」(answer engine optimization)。三個名稱指的是同一個概念。
如何提高網站在LLM的可見度?
值得進一步探討這個話題。根據我作為外行人的理解,有三種主要方法可以提高你在LLM中的可見度:
1. 增加在訓練數據中的可見度
大型語言模型是在龐大的文本數據集上進行訓練的。你的品牌在這些數據中出現的頻率越高,並且與你關注的主題關聯越緊密,在與這些特定主題相關的LLM輸出中就會越明顯。我們無法影響LLM已經訓練過的數據,但我們可以在自己的網站和第三方網站上創建更多與核心主題相關的內容,以便納入未來的訓練輪次中。創建結構良好、與相關主題相符的內容是SEO的核心原則之一——鼓勵其他品牌在其內容中提及你也是如此。結論:這就是SEO。
2. 增加在RAG和基礎數據來源中的可見度
LLM越來越多地使用外部數據來源來提高輸出的時效性和準確性。它們可以搜尋網路,並使用來自Bing和Google等公司的傳統搜尋索引。OpenAI的工程副總裁在Reddit上確認ChatGPT Search使用Bing索引作為其一部分。可以說,在這些數據來源中提高可見度很可能會增加在LLM回應中的可見度。提高在「傳統」搜尋索引中可見度的過程,你猜對了,就是SEO。

3. 濫用對抗性示例
LLM容易受到操控,有可能欺騙這些模型在原本不會推薦你的情況下推薦你。這些是有害的黑客行為,可能帶來短期利益,但長期來看可能會適得其反。
這是——我只是半開玩笑——只是黑帽SEO。
為何GEO與SEO是同一樣東西?
總結這三點,提高LLM輸出可見度的核心機制是:在你的品牌希望建立關聯的主題上創建相關內容,無論是在你的網站上還是其他平台。
這就是SEO。
當然,這種情況可能不會永遠持續。大型語言模型一直在變化,隨著時間推移,搜尋優化和LLM優化之間可能會出現更多差異。但我認為可能會出現相反的情況。隨著搜尋引擎將更多生成式AI整合到搜尋體驗中,而LLM繼續使用「傳統」搜尋索引來作為其輸出的基礎,我認為SEO和GEO之間的界限可能會更小,甚至不存在。
只要「內容」仍然是LLM和搜尋引擎的主要媒介,影響的核心機制可能會保持不變。或者,正如有人在我最近的LinkedIn帖子中評論的:「對於匯總一組信息、對其排序,然後傳播你認為最佳和最準確的結果/信息,能做的方式實在有限。」——Aedan Johnston,Data高級行銷經理,Monks
GEO與SEO的(輕微)差異
我在LinkedIn上分享了上述觀點,收到了一些非常出色的回應。
大多數人同意我的看法,但也有人指出LLM和搜尋引擎之間的一些細微差異,這些值得了解——即使在我看來,這些差異並不足以構成創建新的GEO學科的理由:
1. 「無連結品牌提及」更為重要
這可能是GEO和SEO之間最大、最明顯的區別。無連結提及(unliked mentions)——即在其他網站上撰寫關於你品牌的文字——對SEO的影響很小,但對GEO的影響要大得多。搜尋引擎有許多方式來確定品牌在特定主題上的「權威性」,但反向連結是最重要的方式之一。這是Google的核心洞見:來自相關網站的連結可以作為對被連結網站權威性的「投票」(即所謂的PageRank)。
LLM的運作方式不同。它們對品牌權威性的理解來自頁面上的文字,來自特定詞語的普及度,不同術語和主題的共現,以及這些詞語使用的上下文。無連結內容將增進LLM對你品牌的理解,而這種方式對搜尋引擎沒有幫助。
正如Gianluca Fiorelli在他出色的文章中所寫的:
「品牌提及現在很重要,不是因為它們直接增加『權威性』,而是因為它們強化了品牌作為實體在更廣泛語義網絡中的地位。
當一個品牌在多個(可信的)來源中被提及時:
該品牌的實體嵌入變得更強。
該品牌與相關實體的連接變得更緊密。
該品牌與相關概念之間的餘弦相似度增加。
LLM『學習』到這個品牌在該主題空間中是相關且具有權威性的。」
——Gianluca Fiorelli,策略和國際SEO顧問
許多公司已經重視網站外的提及,只不過帶有一個附帶條件,即這些提及應該是有連結的(且是dofollow)。現在,我可以想象品牌放寬對「好的」網站外提及的定義,對在那些傳統搜尋效益較小的平台上的無連結提及更為滿意。
正如Eli Schwartz所說:
「在這種範式下,連結不需要是超連結(LLM閱讀內容)或限制在傳統網站上。在可信出版物上的提及或在專業網絡上引發的討論(你好,知識庫和論壇)都會在這個框架內提高可見度。」
——Eli Schwartz,增長顧問和策略SEO顧問
使用品牌雷達追蹤品牌提及
你可以使用我們的新工具「品牌雷達」來追蹤你品牌在AI提及中的可見度,從AI概覽開始。
輸入你想要監控的主題,你的品牌(或你競爭對手的品牌),然後查看曝光次數、話語份額,甚至提及你品牌的特定AI輸出:

2. 無關主題的連結和排名不那麼重要
我認為上述觀點的反面也是正確的。如今,許多公司在與其品牌關聯性不大的網站上建立反向連結,並發布與其業務無關的內容,僅僅是為了帶來流量(我們現在稱之為網站信譽濫用)。
這些策略提供足夠的SEO效益,以至於許多人仍然認為值得採用,但它們對LLM可見度的效益會更小。如果這些連結或文章周圍沒有任何相關的上下文,它們將無助於增進LLM對品牌的理解或提高其在輸出中出現的可能性。
3. 不同內容類型對可見度的影響
某些內容類型對SEO可見度的影響相對較小,但對LLM可見度的影響較大。
我們進行了研究,探索哪些類型的頁面最有可能從LLM獲得流量。我們比較了來自LLM和非LLM來源的頁面瀏覽樣本,並比較了這些頁面瀏覽的分佈。我們發現了兩個主要差異:LLM對核心網站頁面和文檔「偏好」,而對列表集合和列表「不喜歡」。對LLM來說,引用比對搜尋引擎更重要。搜尋引擎通常會與創建信息的來源一起顯示信息。LLM將兩者分離,創造了額外需要證明所做聲明真實性的需求。
從這些數據來看,大多數引用屬於「核心網站頁面」類別:網站的首頁、價格頁面或關於頁面。這些是網站的關鍵部分,但並不總是搜尋可見度的重要貢獻者。它們對LLM的重要性似乎更大。
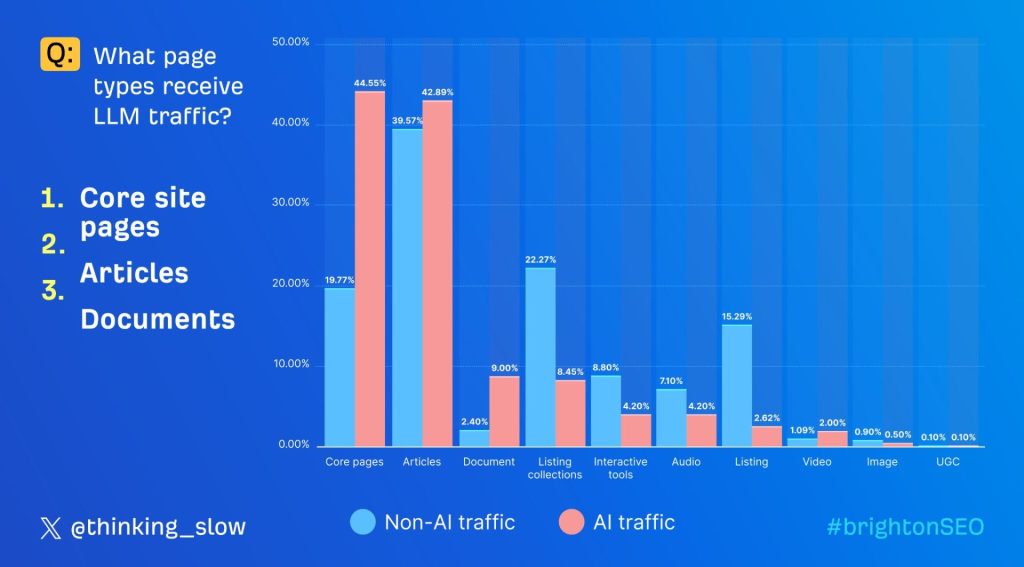
相反,列表頁面——想想那些主要為頁面導航和搜尋可見度而創建的產品大型麵包屑目錄——從LLM獲得的訪問要少得多。即使這些頁面類型不經常被引用,它們也有可能因為不同產品實體的共現而進一步增進LLM對品牌的理解。但考慮到這些頁面通常缺乏上下文,它們的影響可能很小。
最後,網站文檔對LLM似乎也更為重要。許多網站將PDF和其他形式的文檔視為二等公民,但對於LLM來說,它們是一種與其他任何內容來源一樣的內容來源,並且LLM經常在其輸出中引用它們。
實際上,我可以想象公司更加重視PDF和其他被遺忘的文檔,因為它們能夠影響LLM輸出的方式與任何其他網站頁面相同。
4. LLM受益於獨特的文檔結構
LLM可以訪問網站文檔這一點提出了一個有趣的觀點。正如Andrej Karpathy指出的,可能越來越有益於編寫首先為LLM構建的文檔,而對人類相對不可訪問:
「現在是2025年,大多數內容仍然是為人類而不是LLM編寫的。99.9%的注意力即將成為LLM注意力,而不是人類注意力。例如,99%的函式庫(libraries)仍然有基本上渲染為一些漂亮的.html靜態頁面的文檔,假設人類會點擊瀏覽它們。在2025年,文檔應該是一個單一的your_project.md文本文件,旨在進入LLM的上下文窗口。對所有事物都是如此。」
——Andrej Karpathy,Andrej Karpathy
這是對我們應該為人類而不是機器人寫作的SEO格言的顛覆:可能有益於將我們的精力集中在使信息對機器人可訪問,並依靠LLM將信息呈現為更適合用戶的形式。這樣,有特定的信息結構可以幫助LLM正確理解我們提供的信息。
例如,Snowflake提到「全球文檔」的概念。(感謝HubSpot的Victor Pan分享這篇文章。)
LLM通過將文本分解為「塊」來工作;通過在整個文本中添加有關文檔的額外信息(如財務文本的公司名稱和提交日期),LLM更容易理解並正確解釋每個獨立的塊,「將問答準確率從約50%-60%提高到72%-75%的範圍」。
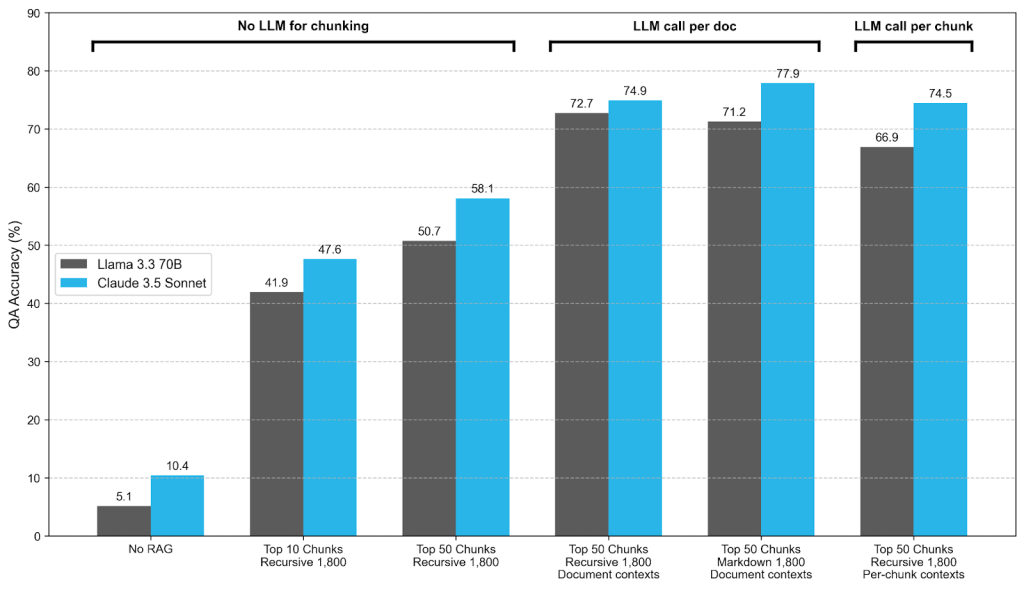
了解LLM如何處理文本為品牌提供了小方法,以提高LLM正確解釋其內容的可能性。
5. LLM訓練的數據對SEO沒有影響
LLM還訓練新型信息來源,這些來源通常超出了SEO的範疇。正如Adam Noonan在X上與我分享的:「公共GitHub內容保證會被訓練,但對SEO沒有影響。」

編碼可以說是LLM最成功的使用案例,開發人員必須佔LLM總用戶的相當大比例。對於某些公司,特別是那些向開發人員銷售產品的公司,可能有益於「優化」這些開發人員最有可能互動的內容——知識庫、公共存儲庫和代碼示例——通過包含有關你的品牌或產品的額外上下文。
6. LLM不渲染JavaScript
最後,正如Elie Berreby解釋的:
「大多數AI爬蟲不渲染JavaScript。沒有渲染器。OpenAI和Anthropic使用的流行AI爬蟲甚至不執行JavaScript。這意味著它們看不到通過JavaScript在客戶端渲染的內容。」
——Elie Berreby,Semking.com高級SEO策略師
這更像是一個腳註而不是主要差異,原因很簡單,我不認為這種情況會長期存在。許多非AI網絡爬蟲已經解決了這個問題,AI網絡爬蟲也很快就會解決。但目前,如果你嚴重依賴JavaScript渲染,你網站的大部分內容可能對LLM不可見。
總結
但關鍵是:管理索引和爬取、以機器可讀方式構建內容、建立網站外提及……這些都感覺像是SEO的經典範疇。
而這些獨特的差異似乎並沒有在大多數品牌的搜尋可見度和LLM可見度之間表現出根本差異:一般而言,在一個方面表現良好的品牌在另一個方面也會表現良好。
即使GEO最終演變為需要新策略,SEO專家——那些職業生涯致力於調和機器和真人需求的人——是最有條件採用這些策略的人。
因此,目前而言,GEO、LLMO、AEO……這一切都只是SEO而已。
